Putting the Concrete Example Together
This section guides the reader through each step of the TQE process described in Section A4. It includes all of the files and artifacts generated throughout the process. Part B of this tutorial gives a deeper explanation of how each of these files is created on the pathway towards calculating a quality rating, and why they are necessary in a TQE.
As a matter of practicality, and as implied in Section A4, a TQE is split into three stages:
- Preliminary Stage
- Error-Annotation Stage
- Automatic Calculation & Follow-Up Stage
A5.1 Preliminary Stage
The purpose of the Preliminary Stage is to:
- Formalize the specifications negotiated when the translation was created,
- Select a metric to be used in later scoring, and
- Prepare the sample for evaluation by segmenting and aligning it.
This is all done in preparation for the Error-Annotation Stage.
The first step of a TQE is to review and ensure access to the translation specifications that were originally negotiated between the requester of the translation and the project manager for the undertaking entity. For ease of data transfer, this is done by means of a structured translation specifications (STS) file, which is an XML file with data fields corresponding to the structured parameters in ASTM F2575.
The metric file is an XML file that contains information essential to the Error-Annotation Stage. It should be tailored to the specifications of the translation project. A metric is composed of three components:
- an appropriate selection of error types,
- a scoring model, and
- a mechanism to determine whether the evaluated translation has passed or failed.
For the concrete example, the Preliminary Stage produces
- an STS .xml file, which contains detailed information on the source and target texts, as well as the translation process,
- a metric .xml file, which contains a list of errors that the evaluator will look for. It also includes information that will later be used to score the translation based on the evaluator’s reporting of those errors, such as the cutscore (the minimum passing score), and
- a bitext.txt file, which includes the source and target texts, concatenated line-by-line, with tab characters as delimiters.
A5.2 Error-Annotation Stage
The purpose of the Error-Annotation Stage is for the evaluator to annotate the bitext using errors from the metric file. The three files from the Preliminary Stage are uploaded to the TRG Annotator Tool, and the evaluator highlights and annotates the errors. In this concrete example, the evaluator determined that there were six errors:
- A minor Organizational Style error in TU1: The style guide for this project requires that the date be formatted “11 November 2015,” not “November 11th, 2015.”
- A major Omission error in TU1: The target text omits the word “electoral” when describing the types of laws mentioned in the EU resolution.
- A major Mistranslation error in TU2: “Retained” is not an acceptable translation of “retenus.” It is a false cognate. An acceptable translation here would be “included.”
- A minor Punctuation error in TU3: The semicolon after “representation” should be a comma.
- A major Unidiomatic Style error in TU4: Although it accurately conveys the intended meaning of the source text, the target text is unwieldy because of the literal word-for-word translation of the source material.
- The evaluator offered an idiomatic alternative: “Prohibiting individuals from holding office as a member of a national parliament and as a Member of the European Parliament at the same time.”
- A minor Awkward Style error in TU5: The phrase “draw up” is unclear. A better alternative might be “establish.”
Once the annotations are complete, the TRG Annotator Tool exports its data as a JSON file.
This data can be converted into a TEI file (TEI is a widely used XML format in the Digital Humanities),
then converted to read-only HTML so that it can be visually inspected for data integrity. This read-only HTML was used in Section A4 to introduce the concrete example text with error annotations.
A5.3 Automatic Calculation & Follow-Up Stage
The purpose of the Automatic Calculation Stage is to obtain a quality rating by comparing a calculated overall quality score to a minimum threshold value called the cutscore. For this concrete example, we use a tool called the TQE Calculator, which receives two files as inputs:
- the TEI file containing error data exported by the TRG Annotator Tool, and
- the metric file, containing scoring model parameters.
The TQE Calculator automatically parses these files and generates an error-count table, which summarizes the number and type of errors that were annotated in the TRG Annotator Tool, as well as those error types’ weights and the penalty multipliers for each severity type.
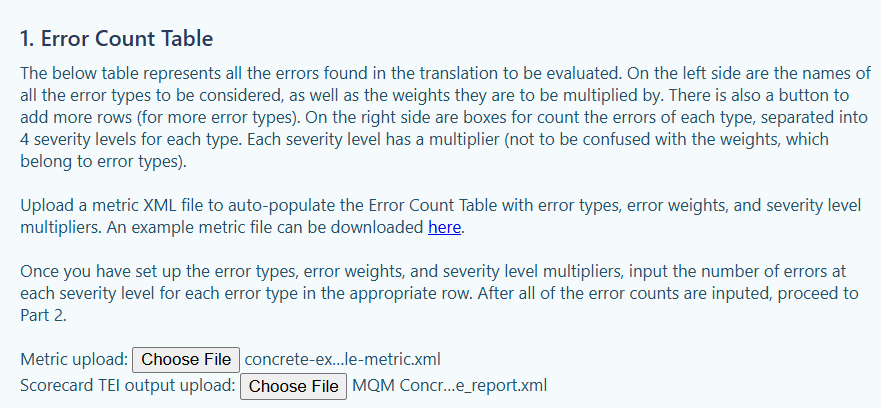
Left Side
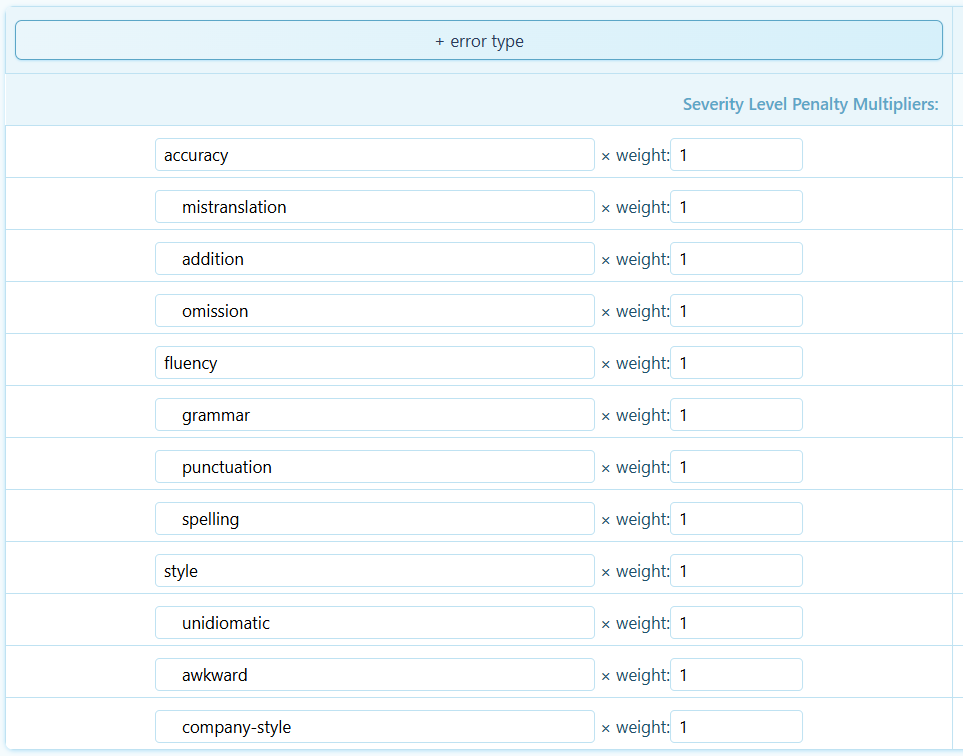
Right Side
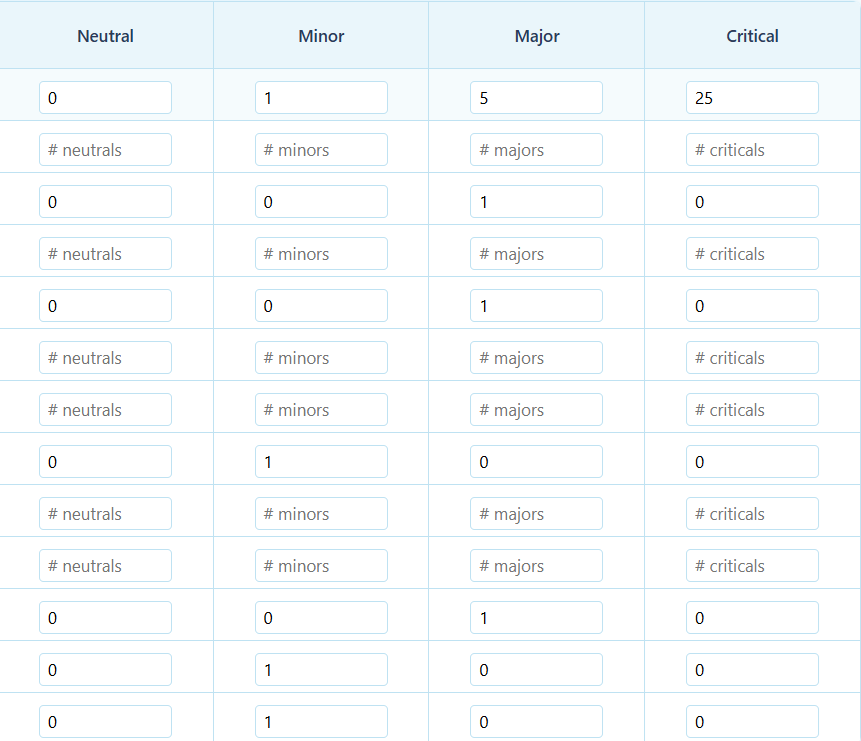
The error-count table contains all the information necessary to calculate the Absolute Penalty Total (APT), where each error, initially worth one penalty point, is first multiplied by its weight (here, all weights are one), and then by its severity multiplier (here, we use ×1 for minor errors and ×5 for major errors). The TQE Calculator automatically computes the APT using the error-count table.
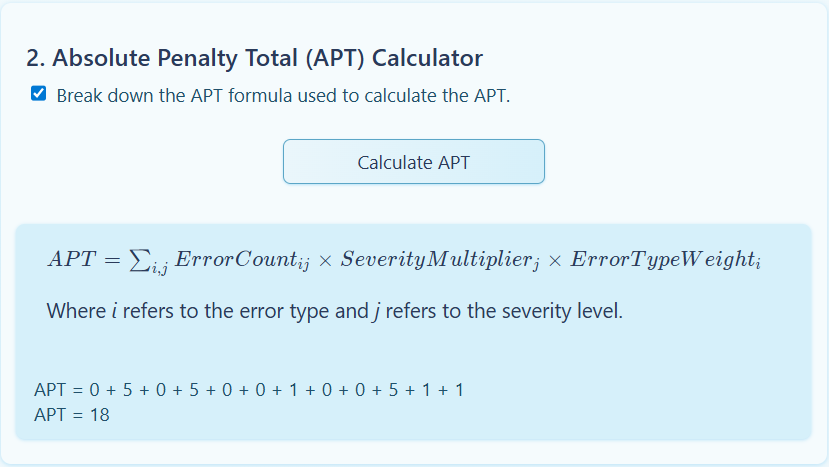
Then, the TQE Calculator automatically extracts the inputs to be used in the scoring model. The only parameter that needs to be explicitly input into the tool is the length of the target-text portion of the document in words (the Evaluation Word Count, EWC), which will be 1300 here. The tool calculates an overall quality score, which is then compared to the cutscore to provide a quality rating:
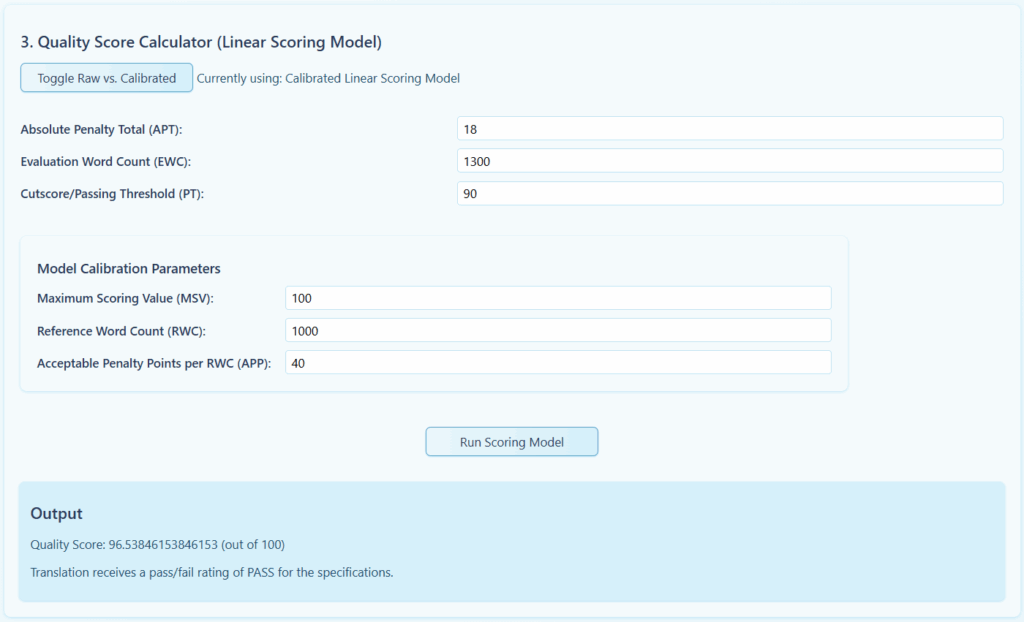
The Overall Quality Score (OQS) is about 96.5 out of 100. This exceeds the established cutscore of 90 and thus, receives a quality rating of “pass,” meaning that the scoring model predicts that a human would find the translation acceptable given the errors (18 penalty-points’ worth) spread out over the text (1300 words).
It is possible to download a summary of this whole process as an Excel spreadsheet.
In this example, we used a linear calibrated scoring model. The exact formulas used in the different scoring models are outside the scope of Part A. To learn more about scoring models, such as the differences between linear scoring models with and without calibration, see Part B, especially Section B1.2.2.
Now, Part B will describe how to expand these procedures to perform a TQE on any real-world translation, when the reader feels ready.